HTTP Basics for Web Development Beginners - Episode 1
An Overview
If you're just starting out in web development, then one very fundamental thing to learn on your journey will be HTTP. Many Developers learn it bit by bit over the course of years. Learning the basics in the very beginning can potentially help you to (faster) identify, understand and solve many problems in the projects you will build. In this post I'll start with a very basic overview.
This series is currently planned to have 6 parts in the end. If you already basically understand how it works you can probably skip this post. I just want to start it off with absolutely no prior knowledge required. Following articles will go much more into detail.
What is HTTP?
HTTP is the main protocol used on the internet to fetch resources. More precisely it's a system of rules for exchanging messages between computers.
Why we use the term "resources" and not just websites instead? Because websites aren't the only things transmitted via HTTP. There's also a lot of data resources (like so called REST APIs, or XML Feeds and more) served via http that are not primarily consumed by end users directly, but instead automatically read by programs. Or to be precise: you also don't consume websites directly. Instead, the browser reads the HTML, CSS, JS code, images and even other resources and assembles the parts for you to a nice looking website. At least if the designers and/or developers behind it did a good job 😉.
How it works
You could picture the whole process just like an old school mail order worked back in the days. You wanted to have something, and therefore you sent an order form via mail to a certain address. The merchant then replies to you by sending you the desired goods in return.So we have request (order form), response (package) and an address system (urls) to locate sender and recipient.
How websites work in the browser
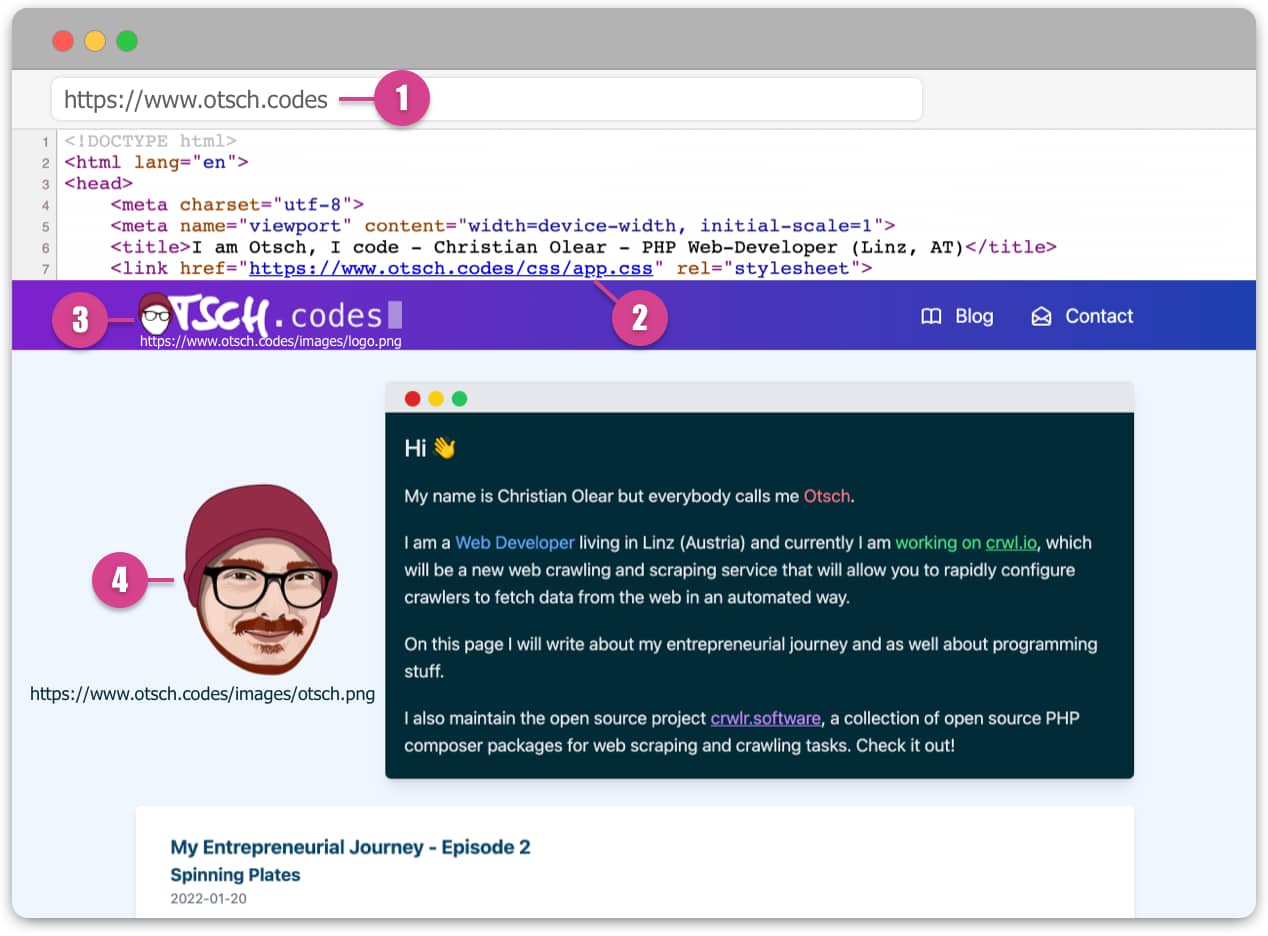 As mentioned before, you don't __directly__ consume websites. When fetching
https://www.otsch.codes, the browser first just receives the __HTML source
code__, which contains __references to further resources__ like CSS (add styling
to the page) and images. "References" means that they are separated files
not included with the response, but instead the browser should fetch them
from the URLs (addresses) defined in the source code.
As mentioned before, you don't __directly__ consume websites. When fetching
https://www.otsch.codes, the browser first just receives the __HTML source
code__, which contains __references to further resources__ like CSS (add styling
to the page) and images. "References" means that they are separated files
not included with the response, but instead the browser should fetch them
from the URLs (addresses) defined in the source code.
And you can see that it does so in your browser's dev-tools. You can open the dev-tools with the same shortcuts in almost all modern browsers:
Mac: Command + Option + i
Windows / Linux: Control + Shift + I (or also F12 for Chrome and Edge)
If dev-tools are new to you, remember the shortcut. It's a very useful
tool belt.
So what you can see there in the network tab is:
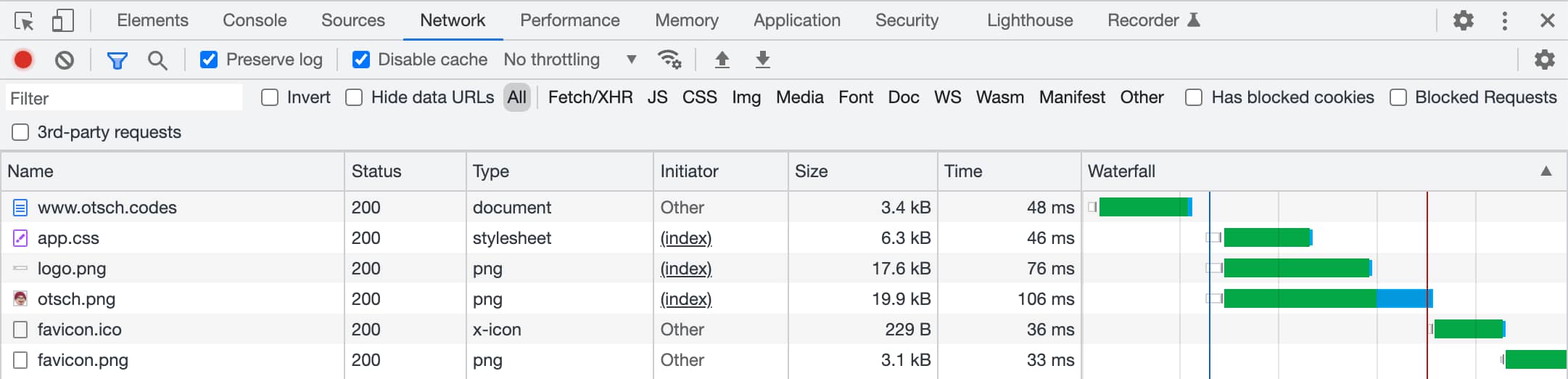
It first loads the HTML source code, parses it and then gets all the referenced resources.
What's next?
Probably there was nothing new for you in this article. I just wanted to really start with absolutely no prior knowledge required. Following articles will cover:
- URLs/URIs
- Messages
- Requests
- Responses
- Headers and what they can be used for
- HTTP/2 (maybe also some words about upcoming HTTP/3)