Ausgewählte Referenzprojekte
Eine Auswahl an Webanwendungen, die ich umgesetzt und teilweise auch selbst konzipiert habe und die ich laufend weiterentwickle.
crwl.io
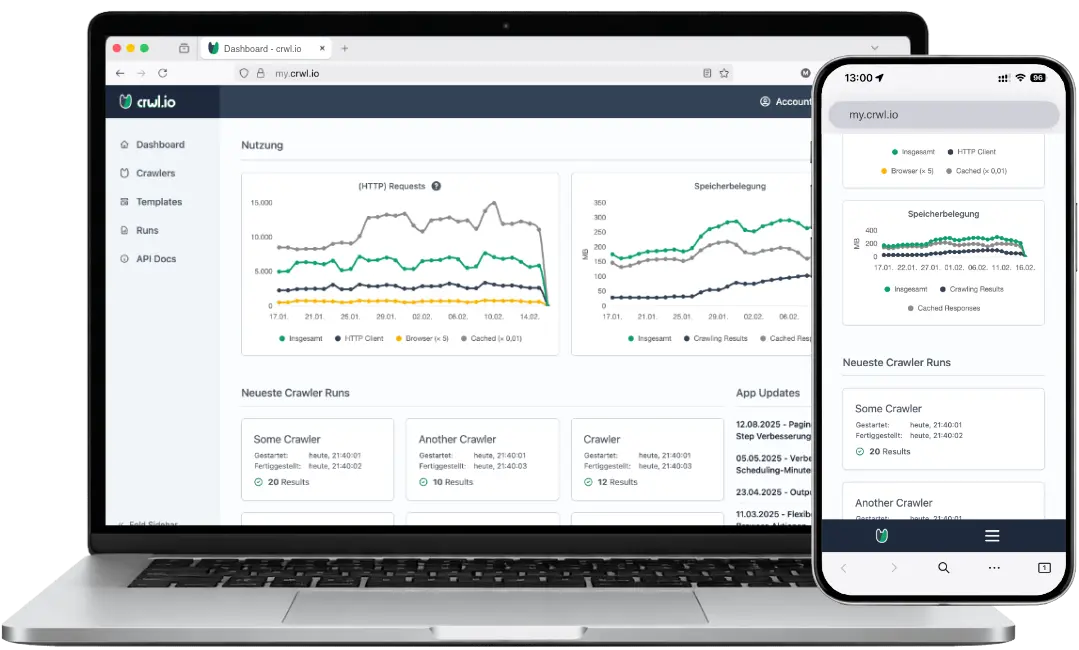
Web Crawling & Scraping Service
Meine Rolle
crwl.io ist eine Eigenentwicklung. Konzeption, Architektur, Design und Programmierung erfolgen vollständig in eigener Verantwortung.
Beschreibung
crwl.io ist eine Software-as-a-Service Dienst zur automatisierten Sammlung und Extraktion von Daten aus dem Internet. Die Anwendung ermöglicht es Ihnen, Crawler über eine benutzerfreundliche Oberfläche nach Ihren Anforderungen zu konfigurieren – auch ohne eigene Programmierkenntnisse.
Einmal konfiguriert, lassen sich Crawler jederzeit manuell ausführen oder zu festen Zeitpunkten automatisiert starten. Über Webhooks und eine API können die gewonnenen Daten strukturiert weiterverarbeitet und in eigene Anwendungen oder Systeme integriert werden.
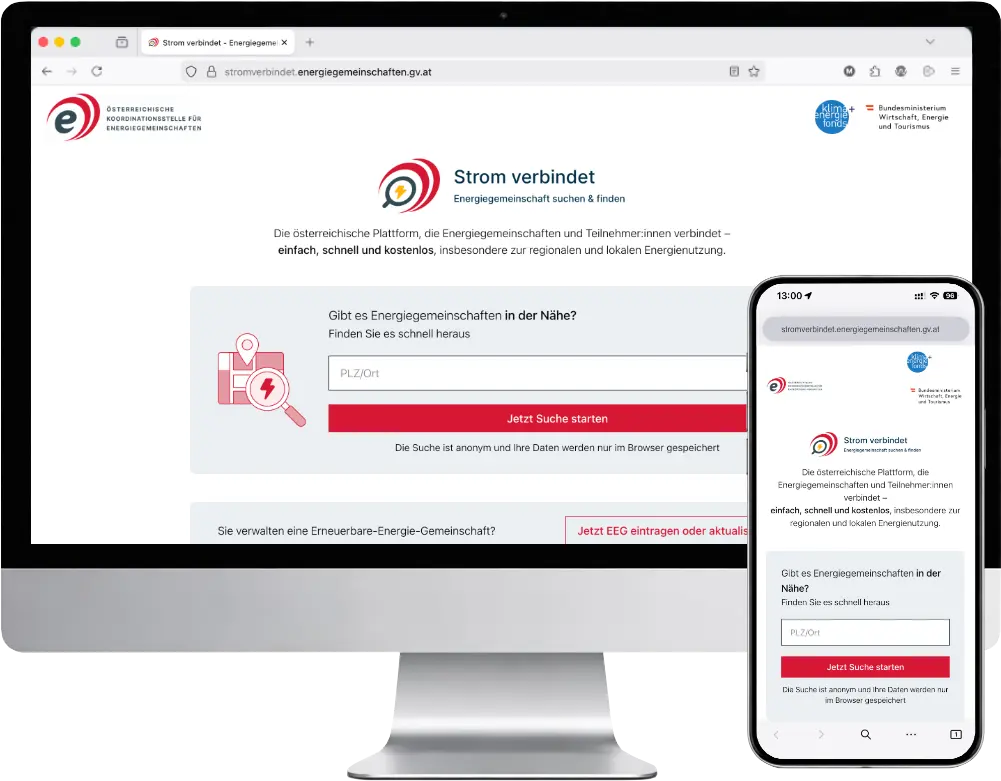
Strom verbindet
Energiegemeinschaft suchen & finden
Meine Rolle
Als Entwicklungspartner der Autonoma Energy GmbH durfte ich die technische Umsetzung des konzeptionell bereits sehr gut aufbereiteten Projekts für die Arbeitsplattform Energiegemeinschaften übernehmen.
Beschreibung
Strom verbindet ist eine Plattform zur Vernetzung von Energiegemeinschaften mit potenziellen Teilnehmer:innen. Energiegemeinschaften können sich dort präsentieren, während Interessierte gezielt nach passenden Gemeinschaften suchen und diese vergleichen können.
crwlr.software
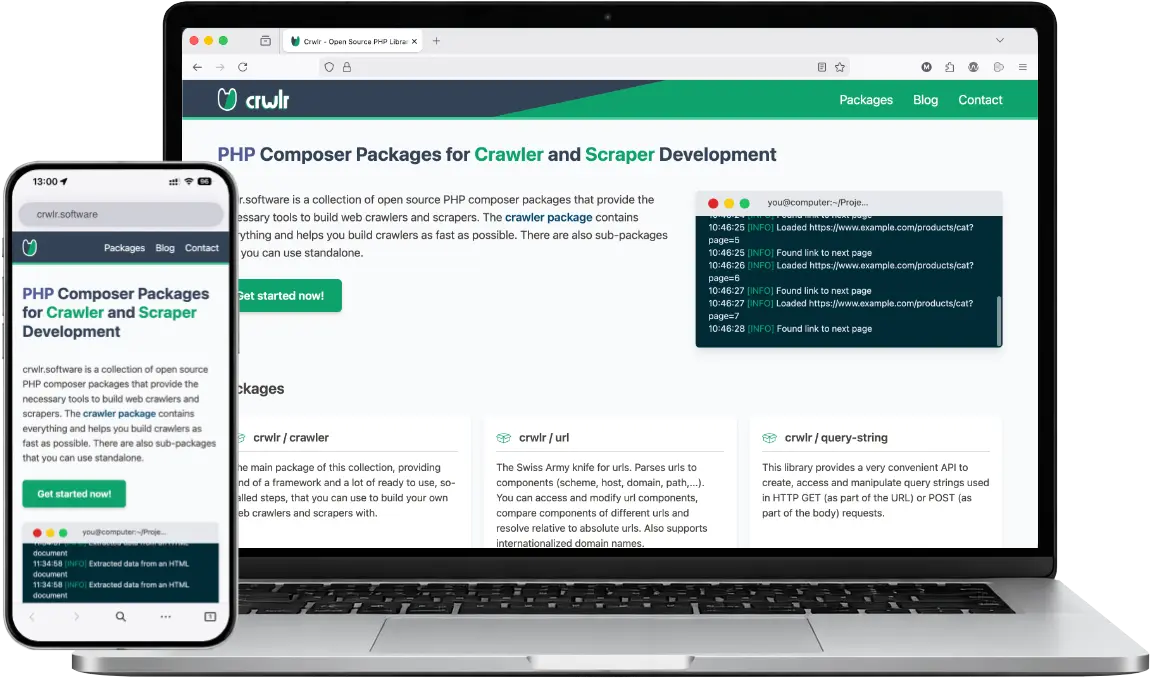
Open Source PHP Library für Web Crawling & Scraping
Meine Rolle
Eigenentwicklung der zugrunde liegenden PHP Library sowie Konzeption und Umsetzung der Dokumentations-Website. Die Weiterentwicklung der Pakete erfolgt überwiegend in eigener Verantwortung, vereinzelt ergänzt durch Beiträge aus der Entwickler-Community.
Beschreibung
crwlr.software ist die Dokumentations- und Projektseite der von mir entwickelten PHP-Library für Web Crawling und Scraping, die zugleich das Fundament von crwl.io bilden. Das Projekt umfasst mehrere eigenständig verwendbare PHP-Composer-Packages, die im zentralen crawler-Package zusammengefasst sind und die schnelle und unkomplizierte Entwicklung individueller Crawler ermöglichen.
Im Unterschied zu vielen vergleichbaren Libraries liegt der Schwerpunkt stärker auf Crawling-Funktionalitäten. Während andere Lösungen primär auf das Extrahieren von Inhalten aus einzelnen Seiten (Scraping) fokussieren, bietet crwlr zusätzlich umfassende Möglichkeiten zur Weiterverfolgung von Links sowie zum automatisierten Laden und Verarbeiten ganzer Seitenstrukturen (Crawling).
Die Library ist zudem nicht auf HTML-Dokumente beschränkt, sondern unterstützt auch die Verarbeitung von XML-, JSON- und CSV-Datenformaten.