Selected Projects
A selection of web applications I have implemented and partly conceived myself, which I actively develop and maintain.
crwl.io
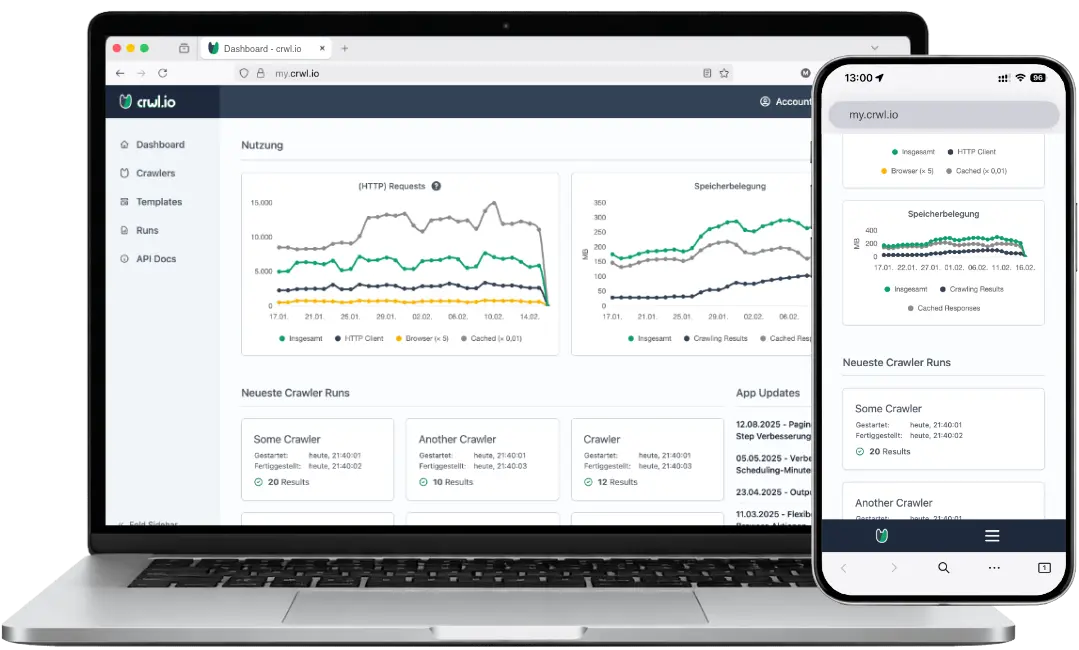
Web Crawling & Scraping Service
My Role
crwl.io is an in-house development. Concept, architecture, design and implementation are carried out entirely under my responsibility.
Description
crwl.io is a software-as-a-service solution for the automated collection and extraction of data from the internet. The application allows users to configure crawlers through a user-friendly interface according to their requirements — even without programming knowledge.
Once configured, crawlers can be executed manually at any time or scheduled to run automatically at defined intervals. Using webhooks and an API, the collected data can be processed further and integrated into custom applications or existing systems.
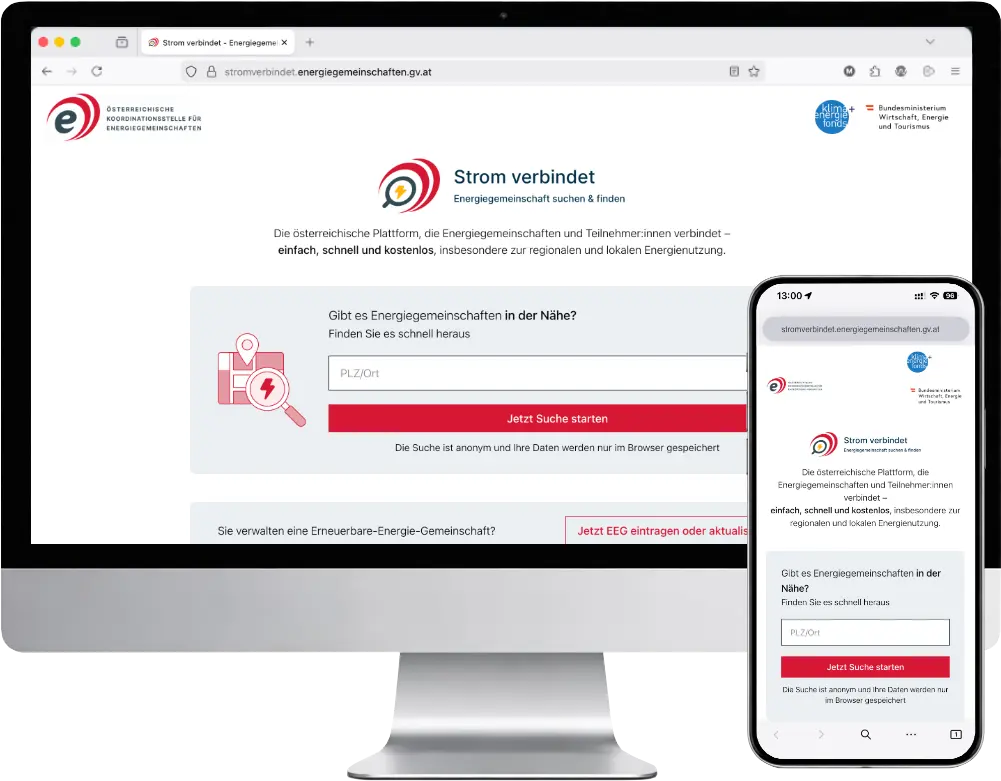
Strom verbindet
Energiegemeinschaft suchen & finden
My Role
As a development partner of Autonoma Energy GmbH, I was responsible for the technical implementation of the project, which had already been thoroughly prepared at a conceptual level, for the Arbeitsplattform Energiegemeinschaften.
Description
Strom verbindet is a platform for connecting energy communities with potential participants. Energy communities can present themselves on the platform, while interested individuals can search for suitable communities and compare them.
crwlr.software
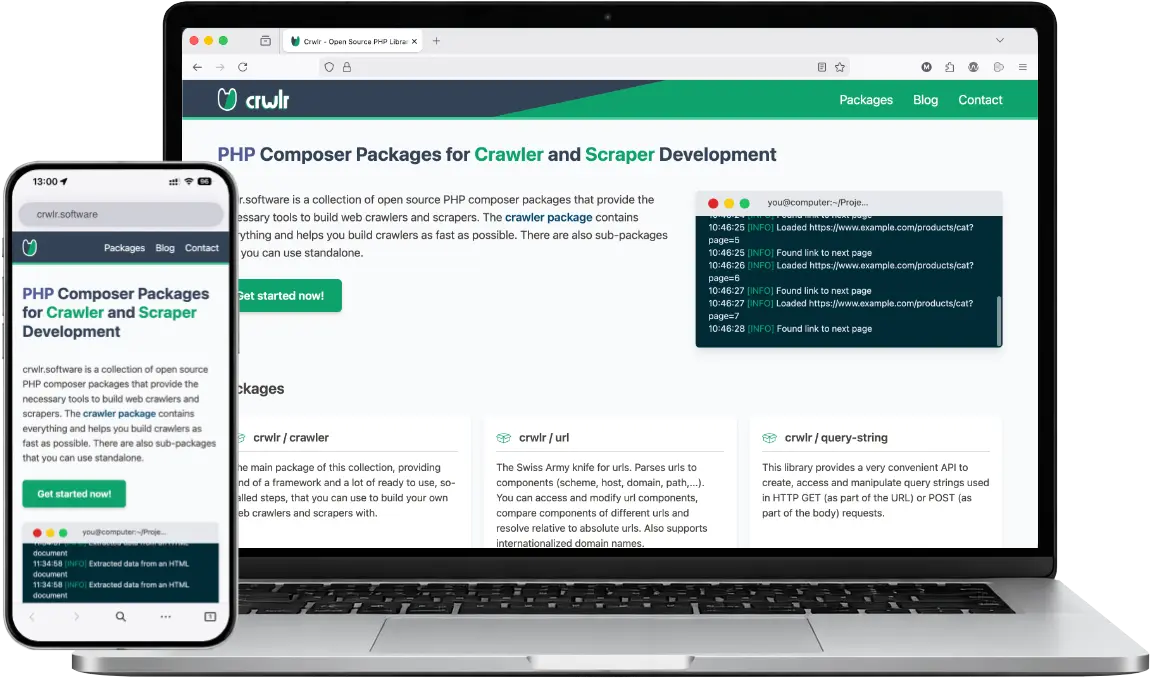
Open Source PHP Library for Web Crawling & Scraping
My Role
Development of the underlying PHP library as well as design and implementation of the documentation website. The ongoing development of the packages is carried out primarily under my responsibility, occasionally complemented by contributions from the developer community.
Description
crwlr.software is the documentation and project website for the PHP library I have developed for web crawling and scraping, which also form the foundation of crwl.io. The project consists of several independently usable PHP Composer packages, combined in a central crawler package that enables the fast and straightforward development of custom crawlers.
In contrast to many comparable libraries, crwlr places a stronger emphasis on crawling functionality. While other solutions primarily focus on extracting content from individual pages (scraping), crwlr additionally offers comprehensive features for following links and automatically loading and processing complete page structures (crawling).
Aditionally, the library is not limited to HTML documents but also supports the processing of XML, JSON, and CSV data formats.